%%capture
!pip install spacy
!pip install scattertext
!pip install tika
!pip install spacytextblobNatural Language Processing
Workshop 4 
Background
Exxon Mobil is the 4th largest oil company in the world. In 1978, an Exxon scientist named James Black wrote an internal briefing called “The Greenhouse Effect” in which he warned: “Present thinking holds that man has a time window of five to ten years before the need for hard decisions regarding changes in energy strategies might become critical.”
Rather than acting on this information, Exxon spent the next forty years aggressively funding climate denial. Recently, a U.S. court ruled that ExxonMobil must face trial over accusations that it lied about the climate crisis and covered up the fossil fuel industry’s role in worsening environmental devastation.
Earnings Calls
Every three months, Exxon conducts an “earnings call”; a conference call between the management of a public company, analysts, investors, and the media to discuss the company’s financial results during a given reporting period, such as a quarter or a fiscal year.
You can register to attend their next one if you want! No worries if you miss it, they provide transcripts on their website.
These transcripts provide an intimate window into the company’s dealings. We can see how much pressure investors are putting on the company to tackle climate change, and how the company responds.
We’ll be working with transcripts spanning nealry 20 years and over 10 million words; that’s like reading the Harry Potter series 10 times. Then, we’ll look at a sample of 100,000 tweets that use the #ExxonKnew hashtag, and analyze public pressure on the company.

Downloading the Data
Let’s grab the data we will need this week from our course website and save it into our data folder. If you’ve not already created a data folder then do so using the following command.
Don’t worry if it generates an error, that means you’ve already got a data folder.
#Make a ./data/wk4 directory
!mkdir data
!mkdir data/wk4mkdir: data: File exists
mkdir: data/wk4: File exists!curl https://storage.googleapis.com/qm2/wk4/Exxon.json -o data/wk4/Exxon.json % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 10.5M 100 10.5M 0 0 13.1M 0 --:--:-- --:--:-- --:--:-- 13.2Mimport spacy
import json
import pylab
from IPython.core.display import display, HTML
import nltk
from tika import parser
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from spacytextblob.spacytextblob import SpacyTextBlob
%matplotlib inline
pylab.rcParams['figure.figsize'] = (10., 8.)
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe('spacytextblob')TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updatesDownloading and reading one earnings call
Exxon host earnings calls on their website in PDF form. Usually, working with PDFs is a real pain as they are not machine-readable. Using a python package called tika, we can “parse” a pdf, turning it into machine-readable text:
# define the URL where your PDF lives. You could also upload your own pdf.
#url='https://corporate.exxonmobil.com/-/media/Global/Files/investor-relations/quarterly-earnings/earnings-transcripts/2022-earnings-transcripts/1Q22-XOM-Earnings-Call-Transcript-4-29-22.pdf'
url='https://d1io3yog0oux5.cloudfront.net/_74d009918ead0ec6acdd6bbaf27a8316/exxonmobil/db/2288/22123/earnings_release/XOM+2Q23+Earnings+Press+Release+Website.pdf'
# parse the pdf by feeding tika the URL and store the text in an object called "raw"
raw = parser.from_file(url)2022-10-27 08:18:46,398 [MainThread ] [INFO ] Retrieving https://corporate.exxonmobil.com/-/media/Global/Files/investor-relations/quarterly-earnings/earnings-transcripts/2022-earnings-transcripts/1Q22-XOM-Earnings-Call-Transcript-4-29-22.pdf to /tmp/media-global-files-investor-relations-quarterly-earnings-earnings-transcripts-2022-earnings-transcripts-1q22-xom-earnings-call-transcript-4-29-22.pdf.
INFO:tika.tika:Retrieving https://corporate.exxonmobil.com/-/media/Global/Files/investor-relations/quarterly-earnings/earnings-transcripts/2022-earnings-transcripts/1Q22-XOM-Earnings-Call-Transcript-4-29-22.pdf to /tmp/media-global-files-investor-relations-quarterly-earnings-earnings-transcripts-2022-earnings-transcripts-1q22-xom-earnings-call-transcript-4-29-22.pdf.
2022-10-27 08:18:46,901 [MainThread ] [INFO ] Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar to /tmp/tika-server.jar.
INFO:tika.tika:Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar to /tmp/tika-server.jar.
2022-10-27 08:18:47,623 [MainThread ] [INFO ] Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar.md5 to /tmp/tika-server.jar.md5.
INFO:tika.tika:Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar.md5 to /tmp/tika-server.jar.md5.
2022-10-27 08:18:48,084 [MainThread ] [WARNI] Failed to see startup log message; retrying...
WARNING:tika.tika:Failed to see startup log message; retrying...
2022-10-27 08:18:53,099 [MainThread ] [WARNI] Failed to see startup log message; retrying...
WARNING:tika.tika:Failed to see startup log message; retrying...Now, we have an object called “raw” that contains some useful information. Notice the squiggly brackets; this is a dictionary. It contains several fields, including some useful metadata such as the author
date=raw['metadata']['dcterms:created']
title=raw['metadata']['dc:title']
raw_text=raw['content']
print('Date: ', date)
print('Title: ', title)
print('Word Count: ', len(raw_text))
print('Text:')
raw_textlook at that! we’re beginning to give some structure to our text data. But suppose I wanted to analyze multiple earnings calls; I need to organize this data so that it can accomodate new entries. As always, we want to tabularize our data. Let’s create a dataframe with three columns (Date, Title, and Text) in which each row is one earnings call:
# create a dataframe using the above data
call=pd.DataFrame({'Date':[date],'Title':[title],'Text':[raw_text]})
# remember, datetime information almost always reaches us as text.
# we need to explicitly convert it to the datetime data type.
call['Date']=pd.to_datetime(call['Date'], infer_datetime_format=True)
# Let's see what we've got.
call| Date | Title | Text | |
|---|---|---|---|
| 0 | 2022-05-04 16:51:56 | 1Q22 XOM Earnings Call Transcript 4-29-22 | \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n... |
Now, if we were so inclined, we could use a loop to repeat this process for a large number of earnings calls, yielding a neatly organized dataframe containing the date, title, and text of earnings calls over time. I’ve done this so you don’t have to, and stored it as a file called “Exxon.json”. It spans 2002-2019, and contains over 10 million words’ worth of earnings calls. Let’s take a peek:
df=pd.read_json('data/wk4/Exxon.json')
df| Title | Date | Text | |
|---|---|---|---|
| 0 | Exxon Mobil Corp at Barclays CEO EnergyPower ... | 2019-09-04 | Mr. Woods joined ExxonMobil International in 1... |
| 1 | Q2 2019 Exxon Mobil Corp Earnings Call - Final | 2019-08-02 | NEIL A. HANSEN, VP OF IR & SECRETARY, EXXON MO... |
| 2 | Event Brief of Q2 2019 Exxon Mobil Corp Earn... | 2019-08-02 | . Neil A. Hansen - Exxon Mobil Corporation,VP ... |
| 3 | Exxon Mobil Corp at JPMorgan Energy Conferenc... | 2019-06-18 | So with that, I'll turn it over to you. Thank ... |
| 4 | Exxon Mobil Corp Annual Shareholders Meeting ... | 2019-05-29 | DARREN W. WOODS, CHAIRMAN & CEO, EXXON MOBIL C... |
| ... | ... | ... | ... |
| 177 | Event Brief of Q3 2002 Exxon Mobil Corporati... | 2002-10-31 | OVERVIEW \n\n XOM reported normalized earnings... |
| 178 | Q3 2002 Exxon Mobil Corporation Earnings Con... | 2002-10-31 | In particular, I refer you to factors affectin... |
| 179 | Q2 2002 Exxon Mobil Corporation Earnings Con... | 2002-08-01 | Welcome to Exxon Mobil's teleconference and we... |
| 180 | Abstract of Q2 2002 Exxon Mobil Corporation ... | 2002-08-01 | OVERVIEW \n\n XOM: 2Q02 net income was $2.64b.... |
| 181 | Exxon Mobil Corporation First Quarter 2002 Re... | 2002-04-23 | We also signed a memorandum of understanding t... |
182 rows × 3 columns
Great– we’ve got a structured dataset of earnings calls. But even though the data has structure, the data in the “Text” column still needs some cleaning and processing.
Dirty Words
Text often comes ‘unclean’ either containing tags such as HTML (or XML), or has other issues. We’ve already done a bit of tidying, but it’s been relatively straightforward. Be cautious when committing to a text analysis project - you may spend a great deal of time tidying up your text.
For example, you may have noticed “…” in the text of the first earnings call we downloaded. This is a character (just like “a” or “$”) except it indicates that we want to create a new line. It’s part of the formatting of the pdf. That’s not really useful information to us. Let start by selecting an earnings call; i’ve chosen the 38th in this dataframe:
call=df.iloc[38]
print('Date: ', call['Date'])
print('Title: ', call['Title'])
print('Word Count: ', len(call['Text']))
print('Text:')
call['Text']This call took place on May 25th, 2016. The transcript is over 125,000 words, nearly as long as the third Lord of the Rings book. It would be a pain to read all of it, so we’ll use python to extract insights. Currently, the contents of call["Text"] is a “string”– a sequence of characters. We can do a number of things with strings, including splitting a big string into smaller strings using a specific delimiter and the .split() function. For example, I can break down the whole text of the earnings call roughly into sentences by splitting the string every time I encounter a period (“.”). This returns a list of smaller strings, and if i select the first one using [0], I get the first sentence of this call:
call['Text'].split('.')[0]"I'm Rex Tillerson, I'm the Chairman and Chief Executive Officer of the Exxon Mobil Corporation"Lovely! the first sentence is an introduction by then-CEO Rex Tillerson.

He was CEO of Exxon from 2006 until he retired on January 1st 2017. One month later, he was sworn in as U.S. Secretary of State under Donald Trump. Let’s see what Rex thinks about climate change!
Regular Expressions (Regex)
Another thing we can do with strings in python is search them using regular expressions. A regular expression is a sequence of characters that specifies a search pattern in text. You can play around building some regex queries using this tool.
You can think about this as Ctrl+F on steroids; In its simplest form, we can use regex to search for a character, word, or phrase in a bunch of text. For example, we can use regular expressions to count how many times “climate change” is mentioned in this earnings call using the re.findall() function:
# import the regular expressions library
import re
# use the findall function to search for mentions of "climate change" in the text of our call
climate_change = re.findall(r'climate change', call['Text'], re.IGNORECASE)
# this returns a list of strings matching our search term.
# the length of the list gives us the number of occurances
len(climate_change)11Looks like climate change is mentioned 51 times in this earnings call.
Exercise
how many times is the phrase “global warming” mentioned?
But we have 182 earnings calls in this sample– suppose we want to count the number of times climate change is mentioned in each one, so we can see the salience of this topic over time.
Applying a lambda function to a dataframe
Because each row of our dataframe df is an earnings call (the text of which is contained in df['Text'], we want to apply the analysis we did for the single earnings call above to each row of df.
We can accomplish this using a lambda function. This allows us to iterate over each value in a dataframe column, and apply a function to it. In the simple example below, I use a lambda function to create a new column that is takes the values from a different column and multiplies them by 2:
# create a dataframe called "example" with one column called "numbers" which contains numbers 0-5
example= pd.DataFrame({'numbers':[0,1,2,3,4,5]})
# print the dataframe
print("\n Before applying lambda function: \n", example)
# create a new column called "doubled numbers"
# apply a lambda function that iterates over each row in the "numbers" column
# call each row "x", and multiply it by 2
example['doubled numbers']= example['numbers'].apply(lambda x: x*2)
# print the dataframe, which now contains the new column
print("\n \n After applying lambda function: \n", example)
Before applying lambda function:
numbers
0 0
1 1
2 2
3 3
4 4
5 5
After applying lambda function:
numbers doubled numbers
0 0 0
1 1 2
2 2 4
3 3 6
4 4 8
5 5 10There were simpler ways of doing this (namely, example[doubled numbers]=example['numbers']*2). But if we want to do something more complex, lambda functions are very useful. Remember, we used re.findall(r'climate change', call['Text'], re.IGNORECASE) to get a list of mentions of climate change in the text of one earnings call, and measured the length of the list using len() to count the number of mentions. We can turn this into a lambda function as follows:
df['Text'].apply(lambda x: len(re.findall(r'climate change', x, re.IGNORECASE)))
df['Text']: the column we want to iterate over..apply(lambda x:: iterate over each row in the column, and call each value in that column x. In other words, x will represent the text of each earnings call.len(re.findall(r'climate change', x, re.IGNORECASE)this is exactly the same as what did previously to find the number of mentions of climate change in the one earnings call, except that we swappedcall['Text']withx, since we want to do this for the text of every earnings call.
# create a column called "climate change" that contains the count of mentions of this keyword
df['climate change']=df['Text'].apply(lambda x: len(re.findall(r'climate change', x, re.IGNORECASE)))
# print the title of each earnings call, along with the number of mentions of climate change.
print(df[['Title','climate change']]) Title climate change
0 Exxon Mobil Corp at Barclays CEO EnergyPower ... 0.000045
1 Q2 2019 Exxon Mobil Corp Earnings Call - Final 0.000000
2 Event Brief of Q2 2019 Exxon Mobil Corp Earn... 0.000000
3 Exxon Mobil Corp at JPMorgan Energy Conferenc... 0.000000
4 Exxon Mobil Corp Annual Shareholders Meeting ... 0.000360
.. ... ...
177 Event Brief of Q3 2002 Exxon Mobil Corporati... 0.000000
178 Q3 2002 Exxon Mobil Corporation Earnings Con... 0.000000
179 Q2 2002 Exxon Mobil Corporation Earnings Con... 0.000000
180 Abstract of Q2 2002 Exxon Mobil Corporation ... 0.000000
181 Exxon Mobil Corporation First Quarter 2002 Re... 0.000000
[182 rows x 2 columns]Amazing! We’ve now got a column indicating how many times “climate change” was mentioned in each earnings call.
Exercise
Create three new columns that count the frequency of the terms “global warming”, “carbon capture”, and another phrase or word of your choosing. When you’ve done this, edit the code below so that it not only shows the frequency of “climate change” mentions, but also the three additional columns you created.
Advanced: Our current measure of the number of mentions of keywords might be biased: if one earnings call mentions climate change 10 times more than another, but that earnings call has 10 times more words, then the rate of keyword mentions hasn’t actually increased; people are just talking more. You can get the word count of each earnings call in the lambda function above using len(x) (using len() on a string will get you a word count). Edit the lambda function above such that we don’t get a count of the number of mentions of climate change, but the rate of mentions (i.e., count of “climate change” divided by total word count per call).
Let’s plot the frequency of these mentions over time to analyze temporal trends in the salience of climate change and other keywords in these calls. We’ll accomplish this using
# extract the year from the date column
df['Year']=df['Date'].dt.year
# group the dataframe by year, calculating the sum of the "climate change" column
# save it as a new dataframe called "yearly"
yearly=df.groupby('Year')['climate change'].sum()
# plot yearly
yearly.plot()<matplotlib.axes._subplots.AxesSubplot at 0x7f7d77456890>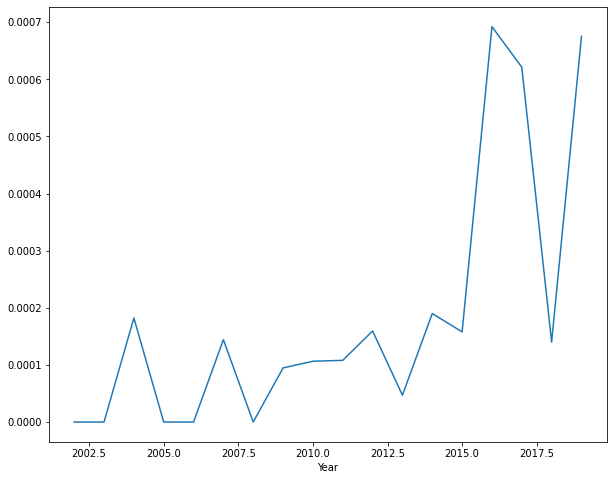
Do you notice any patterns in the salience of these topics over time?
Intermediate Regex
Great. We can see how frequently climate related keywords come up in earnings calls between shareholders and Exxon Mobil representatives over time. But what if we want to look at what they’re actually saying?
We can get a bit fancier with Regex to look at the content of these discussions. Regex can be pretty confusing, but it’s also a very powerful tool. Before moving on, let’s familiarize ourselves a bit more with regex.
Let’s try to extract all sentences containing the phrase “climate change”; the regex would look like this:
([^.]*climate change[^.]*)
()indicates that we want to match a group of characters, not just the characters themselves. In this case, the group is a sentence, not just the word climate change. But how do we[^.]*we want to match all characters except periods. This will break the text up into sentencesclimate changethe phrase we want our sentence to contain.
when you put it all together, the regex will search for groups of characters (1.) bounded by periods (2.) that contain the phrase “climate change” (3.)
# create a list called "climate_sentences" that contains the results of this query
climate_sentences=re.findall(r"([^.]*climate change[^.]*)"," ".join(df['Text']))
print(len(climate_sentences))
# print the first 10 sentences in the list
for sentence in climate_sentences[:10]:
print('\n', sentence)251
However, as the world looks to lower their carbon emissions and respond to the risk of climate change, there is a desire to better understand how robust our plans are to evolving policies and changing market trends
Meeting the growing need for energy and addressing the risk of climate change are not mutually exclusive
Over the past year, I've met with policymakers from both sides of the aisle: NGOs, academia, and participated in a climate change dialogue at the Vatican
Our approach to climate change has 4 components
We don't believe that society has to choose between economic prosperity and reducing the risk of climate change
Recent steps the company has made in the last month to start to make arrangements for dialogue with the Climate Action 100+ group at independent director level are welcome, but the fact that it has taken so long to get to this point reflects how painfully slow progress has been to date with Exxon on climate change
I would tell you that we understand the concerns and share your desire to meaningfully address climate change, and I think ExxonMobil plays a pretty important role in that both today and in the future
The Board's been engaged, and I would tell you, too, that we've had many, many discussions not only with your organization, but with many groups outside who have this concern, and I think are making very good progress in addressing some of the fundamental challenges associated with the risk of climate change
Members of the Board, this week's Economist describes ExxonMobil as a notable laggard on climate change
The next shareholder proposal calls for a specific Board climate change committee, and I understand that Natasha Lamb will present this proposalSemantic Analysis
Now we can see the sentences which mention climate change, which helps us understand a bit about the context. We can perform semantic analysis on some of these sentences to take a close look at the grammar of some of these sentences; I’ve isolated the 9th sentence and produced a dependency tree, like the ones we’ve seen in class.
from spacy import displacy
#run the NLP pipeline on the 9th sentence from our list of sentences about climate change.
doc = nlp(climate_sentences[8].lstrip())
#print out the dependency tree
displacy.render(doc, jupyter=True)The root of this dependency tree is the verb “describes”. The main subject is the Economist, and the object is Exxon. But we’re still missing one vital piece of information: who is speaking? It makes a big difference to our understanding of whats going on. Are mentions of climate change increasing over time because shareholders are asking more questions? Or did CEO Rex Tillerson have a spiritual awakening in which all he wants to do is talk about climate change? For that, we need to figure out who’s talking, and resturcture our dataframe.
Advanced Regex
The earnings call transcript is structured in such a way that it should be possible to separate speakers based on regular expressions. Every time a new person is speaking, they are introduced in the transcript in a new paragraph; Consider the excerpt below:
OPERATOR: Our next question comes from Philip Weiss with Argus Research.
PHILIP WEISS, ANALYST, ARGUS RESEARCH COMPANY: Good morning. I did have one, most of my questions have been answered, but I do have one follow-up on the US. You said that the rig count that's being used for liquids-rich is rising but when I look at production, natural gas as a percentage of your total production has grown, and liquids has actually fallen a little bit. So, I wonder if you can just comment on when we might start to see that trend change?
DAVID ROSENTHAL: Sure. The fall off in the liquids is really just the overall decline in the conventional, as well as some divestments. You'll recall we had a divestment in the Eastern Gulf of Mexico and that had an impact on us year-over-year in particularly in the second half.
In terms of when we'll see significant production growth out of the unconventional, I mentioned some of the increases in percentages, although we haven't given all of the specific production volumes, but we'll do that as we progress.Now, we can’t simply split by new line (\n); David Rosenthal has two paragraphs. We also can’t just split using :, since this may appear in the text other than to indicate speakers. Let’s describe the features of the characters we’re looking to split out:
([A-Z]+.+[A-Z]+:)
- It’s a group of characters * regex:
() - The words are all caps, and can contain any characters * regex:
([A-Z]) - There can be multiple words, and they can be separated by anything * regex:
([A-Z]+.+[A-Z]) - The sequence always ends in a colon * regex:
([A-Z]+.+[A-Z]+:)
Let’s use this regex in re.findall() to get a list of the speakers on this call:
# create a list of all the speakers by searching text of the earnings call for the above regex.
speakers = re.findall(r'([A-Z]+.+[A-Z]+: )', call['Text'])
# because they don't introduce the speaker in the opening statement, insert a placeholder at the beginning of this list.
speakers.insert(0,'INTRODUCTION')
# using set(list) will give you the unique values in a list
# the length of set(list) gives us the number of unique speakers
print('There are', len(set(speakers)),'speakers on this call:')
# let's print out the first 10 speakers:
for speaker in speakers[:10]:
print(speaker)There are 31 speakers on this call:
INTRODUCTION
JEFF WOODBURY, VP OF INVESTOR RELATIONS, CORPORATE SECRETARY, EXXONMOBIL CORPORATION:
REX TILLERSON:
REX TILLERSON:
REX TILLERSON:
BETH RICHTMAN, INVESTMENT MANAGER, CALPERS:
REX TILLERSON:
MICHAEL CROSBY, CAPUCHIN FRANCISCAN FRIAR:
REX TILLERSON:
TRACEY REMBERT, SHAREHOLDER, CHRISTIAN BROTHERS INVESTMENT SERVICES: We want to do more than just identify the speakers though; we want to break up the text of our earnings call into chunks of speech and associate each chunk of speech with its speaker. We can split a string using regular expressions using re.split(<regex>,<text>). This takes one block of text, splits it into chunks using the regex, and returns a list of chunks:
# split the text of the earnings call using our regex, save the list as "speech"
speech=re.split(r'[A-Z]+.+[A-Z]+: ', call['Text'])
# now, we can print the fourth speaker:
print('Speaker: \n', speakers[3])
# and the text of the fourth speech:
print('\n Speech: \n', speech[3])Speaker:
REX TILLERSON:
Speech:
So now, turning to the formal business of the meeting and a few brief remarks on shareholder proposals and voting. Each year, the corporation receives a number of suggestions from shareholders. Some of these are in the form of proposals to be presented at the Annual Meeting and each is given careful consideration.
We seek dialogues with the sponsors prior to the meeting when there is more time to better understand each other's positions and we often find agreement. Let me be clear on the conduct of the meeting. Recognizing that the majority of our shareholders have voted by proxy and are not present, we have established procedures to facilitate an orderly meeting.
We've set up a process for speakers to identify themselves and to express their views and I assure you, we welcome those views. In order that as many shareholders as possible can participate, we have set time limits and a system of reminders to help you manage your time.
We have 14 items to consider. As Secretary Woodberry said earlier, discussion on all items of business will be deferred to the discussion period. This may enable us to have some time for general comments and questions as well and conclude the meeting in a reasonable time frame.
For those of you who may wish to leave the meeting at any time, let me express my appreciation for your attendance. Since we have a number of items yet to discuss on the program and you've been sitting for a while, I would invite you to stand and take a short stretch break and I would ask that you not leave the hall. We'll resume in just a moment.
(Break)
Now we’ve associated chunk of speech with their speaker, amazing. Let’s create a new dataframe that reflects this structure. Currently, our dataframe call has one row. Let’s use the two lists we just created, speakers and speech, to create a dataframe in which each row is one chunk of speech. A column called “speaker” will indicate who is speaking, and a column called “speech” will contain the text of the speech:
# create the new dataframe, from the two lists, and name it "speaker_df"
speaker_df=pd.DataFrame({"speaker":speakers,"speech":speech})
# clean up the "speaker" column by removing the colons using .str.replace(":","")
# remove trailing white space using str.rstrip()
speaker_df['speaker']=speaker_df['speaker'].str.replace(':','').str.rstrip()
# print rows in which rex tillerson is speaking:
print(speaker_df[speaker_df['speaker']=="REX TILLERSON"]) speaker speech
2 REX TILLERSON Thank you, Jeff. We will address our items of ...
3 REX TILLERSON So now, turning to the formal business of the ...
4 REX TILLERSON If you'd please take your seats. The first ite...
6 REX TILLERSON Thank you. The Board recommends a vote against...
8 REX TILLERSON Thank you, Fr. Crosby. The Board recommends a ...
10 REX TILLERSON Thank you, Ms. Rembert. The Board recommends a...
12 REX TILLERSON Thank you, Mr. Garland. The Board recommends a...
14 REX TILLERSON Thank you, Mr. Sifferman. The Board recommends...
16 REX TILLERSON Thank you, Mr. Jenkins. The Board recommends a...
18 REX TILLERSON Thank you, Ms. Lamb. The board recommends a vo...
20 REX TILLERSON I'm well. Thank you.\n\n
22 REX TILLERSON Thanks, Sister Pat. The board recommends a vot...
24 REX TILLERSON Thank you, Mr. Mason. The board recommends a v...
26 REX TILLERSON Thank you, Ms. Fugere. The board recommends a ...
28 REX TILLERSON Thank you, Ms. Fugere. The board recommends a ...
29 REX TILLERSON Okay, let's resume the meeting, so if you woul...
30 REX TILLERSON There in the back.\n\n
32 REX TILLERSON Thank you. Other speakers? All right, down her...
34 REX TILLERSON Well, ALEC, as you probably know, is an organi...
36 REX TILLERSON Well, as you and I have spoken before, my view...
38 REX TILLERSON I understand, and so I'm going to respond to a...
40 REX TILLERSON Thank you. In the inside aisle here.\n\n
42 REX TILLERSON Speculating on future court events would be ir...
44 REX TILLERSON The only way I know to respond is to tell you ...
46 REX TILLERSON And we have responded to those allegations as ...
48 REX TILLERSON Could you begin to wrap it up?\n\n
50 REX TILLERSON Thank you. So over here to this side of the ha...
52 REX TILLERSON Well, as to Saudi Aramco's views or the Kingdo...
54 REX TILLERSON I wish my dad had bought some shares the year ...
56 REX TILLERSON Thank you for those kind words. Right here.\n\n
58 REX TILLERSON We will continue to engage in the policy discu...
59 REX TILLERSON I believe all the items of business have been ...
60 REX TILLERSON While the inspectors of election are preparing...
62 REX TILLERSON Well, I'm not sure I would characterize it as ...
64 REX TILLERSON Well, as many of have heard me say before, if ...
65 REX TILLERSON The inspectors of election are ready to report...
67 REX TILLERSON Thank you. As stated in the written report of ...Analyzing Distinguishing Terms
And there we have it. We started with a PDF on a website, and we’ve ended up with a dataframe in which each row is a speech, with a column indicating who is speaking, what they’re saying, and when they said it.
Now, lets use this dataframe to create a scatterplot comparing the language used by the company’s CEO Rex Tillerson and the company’s shareholders.This will give us insights into the topics that are important for shareholders, and the debates that take place within the company.
We’ll do so using the scattertext libray:
%%capture
import scattertext as st
# create a corpus of text from the dataframe
corpus = st.CorpusFromPandas(speaker_df, # load the dataframe
category_col='speaker', # indicate which column contains the category we want to distinguish by
text_col='speech', # indicate which column stores the text to be analyzed
nlp=nlp).build() # load the NLP models used for analysis
# remove stopwords from the corpus of text
corpus=corpus.remove_terms(nlp.Defaults.stop_words, ignore_absences=True)
# now, we create the scatterplot
html = st.produce_scattertext_explorer(
corpus, # load the corpus
category="REX TILLERSON", # indicate which category value we want to compare against all others; in this case, all rows in which "REX TILLERSON" is the speaker
category_name='Rex Tillerson', # set the label on the plot as "Rex Tillerson"
not_category_name='Others', # set the label on the plot for all other speakers as "Others"
width_in_pixels=1000) #set the width The plot above compares the frequency of terms used by Exxon CEO Rex Tillerson (on the Y axis) against those used by other speakers (mainly shareholders, on the X axis). The top right corner will contain terms used frequently by both groups. the bottom left corner contains terms used infrequently by both groups. The top left corner contains terms used frequently by Rex Tillerson, but infrequently by shareholders. The bottom right corner contains terms used frequently by shareholders, but infrequently by Rex Tillerson.
A list of top terms used by each group is shown in the right. On this list, we can see that “climate change” is the 4th most common phrase used by the “Others” category, but isn’t even in the top ten for Rex. If you click on “climate change” in this list, it will give you some statistics on how frequently this term is used by each group, as well as a selection of example sentences in which the term appears. You can search for other words/phrases either by clicking on them in the scatterplot, or entering them into the “Search the chart” box below the scatterplot.
Exercise
Search for “ALEC” in this plot, and then google the term to find out more about what this is. What are shareholders aiming to do regarding ALEC, and how does Tillerson respond?
Search for the term “carbon”. What differences do you notice in the use of this term by Rex Tillerson versus the shareholders?
Use this plot to identify another topic that shareholders are pressuring Exxon about.
External pressure
The fact that Exxon knew about climate change in the 1970s and still funded climate denial resulted in public outrage, culminating in an online movement organized around the twitter hashtag #ExxonKnew.
I’ve downloaded almost 100,000 tweets containing the hashtag #ExxonKnew, between 2016 and 2017. Work together as a group to explore and analyze this dataset.
!curl https://storage.googleapis.com/qm2/wk4/Exxon_tweets_clean.csv -o data/wk4/Exxon_tweets_clean.csvtweets=pd.read_csv('data/wk4/Exxon_tweets_clean.csv')
tweets| Unnamed: 0 | text | created_at | author_id | lang | geo | latitude | longitude | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | #ClimateChangeIsReal #climateChange #PutinPupp... | 2016-12-31T22:45:29.000Z | 22220344.0 | qme | NaN | NaN | NaN |
| 1 | 1 | What you should know about @latimes connection... | 2016-12-31T22:42:18.000Z | 31413260.0 | en | NaN | NaN | NaN |
| 2 | 2 | RT @EnergyInDepth: Legal experts say attack on... | 2016-12-31T22:17:33.000Z | 7.59e+17 | en | NaN | NaN | NaN |
| 3 | 3 | RT @anneli8012: @Khanoisseur yep, Exxon knew a... | 2016-12-31T21:40:05.000Z | 8e+17 | en | NaN | NaN | NaN |
| 4 | 4 | Former NY AG: N.Y.’s ExxonMobil overreach http... | 2016-12-31T20:05:36.000Z | 7.5e+17 | en | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 89096 | 89085 | RT @billmckibben: Next shoe drops in #exxonkne... | 2016-01-01T00:16:01.000Z | 885173964.0 | en | NaN | NaN | NaN |
| 89097 | 89086 | Así ha transcurrido el día más caliente regist... | 2016-01-01T00:12:27.000Z | 30540898.0 | es | NaN | NaN | NaN |
| 89098 | 89087 | RT @Mdettinger: While undermining public confi... | 2016-01-01T00:07:08.000Z | 490991866.0 | en | NaN | NaN | NaN |
| 89099 | 89088 | RT @greenpeaceusa: Lying for profit is called ... | 2016-01-01T00:06:10.000Z | 4182290233.0 | en | NaN | NaN | NaN |
| 89100 | 89089 | RT @billmckibben: Thanks to @democracynow for ... | 2016-01-01T00:01:39.000Z | 11186572.0 | en | NaN | NaN | NaN |
89101 rows × 8 columns
Sentiment Analysis
Sentiment analysis is the computational study of people’s opinions, sentiments, emotions, appraisals, and attitudes towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes. Let’s study the sentiment of the tweets in this dataset.
spacytextblob performs sentiment analysis using the TextBlob library. Adding spacytextblob to a spaCy nlp pipeline creates a new extension attribute for the Doc.
The ._.blob attribute contains all of the methods and attributes that belong to the textblob.TextBlob class. Some of the common methods and attributes include:
._.blob.polarity: a float within the range [-1.0, 1.0].._.blob.subjectivity: a float within the range [0.0, 1.0] where 0.0 is very objective and 1.0 is very subjective.._.blob.sentiment_assessments.assessments: a list of polarity and subjectivity scores for the assessed tokens.
Let’s run sentiment analysis on a single tweet:
# grab the 130th row in the dataframe and select the text of the tweet
text=tweets.iloc[130]['text']
# apply the NLP pipeline to this text.
doc = nlp(text)
print(text)
print('Polarity: ', doc._.blob.polarity)
print('Subjectivity: ', doc._.blob.subjectivity)
print('Assessments: ', doc._.blob.sentiment_assessments.assessments)RT @Exxon_Knew: Stop saying #Tillerson is good on climate. He leads the oil company WORST on climate #ExxonKnew via @jacobwe https://t.co/P…
Polarity: -0.15000000000000002
Subjectivity: 0.8
Assessments: [(['good'], 0.7, 0.6000000000000001, None), (['worst'], -1.0, 1.0, None)]We can see that the model has deemed this tweet to be expressing negative sentiment: it has a polarity of -0.15. It also deems this to be a pretty subjective tweet, with a subjectivity score of 0.8. It does indeed appear to be expressing a subjective opinion. Finally, we can see which words are leading to this assessment. The word “good” is leading to a 0.7 increase in the polarity score, and a 0.6 increase in the subjectivity score. The word “worst” is leading to a -1 change polarity, and a +1 change in subjectivity. The overall scores are weighted averages of these values. Though these scores do roughly align with the actual sentiment of this tweet, ALWAYS pay attention to whats going on inside of your sentiment analysis pipeline. Even though the overall sentiment score here is negative, it should probably be even more negative; the algorithm picked up on the word “good” in this tweet, and this improved the polarity score by 0.7. But the context in which “good” was uttered in this tweet is actually negative! the person is saying “stop saying #Tillerson is good on climate”– this is expressing negative sentiment!
Assessed Question
In this assessed question, we will use NLP to find the biggest hater.
I’ve pulled a sample of 1000 tweets. In the code cell below:
- Using a lambda function,
.apply(lambda x: nlp(x)._.blob.polarity), create a column in the sample dataframe that contains the polarity of each tweet. - Create a column that contains the subjectivity score for each tweet.
- Filter the dataframe to keep only the tweets that are subjective (subjectivity score > 0.5) and tweets that have negative sentiment (polarity score < 0).
Which twitter user (author_id) has the lowest total sentiment?
sample= tweets.sample(1000, random_state=1)